
Tableau version 2020.2 – Un nouveau modèle de données

Régulièrement, Tableau Software publie de nouvelles versions de ses applications afin de partager les nouvelles fonctionnalités avec ses utilisateurs.
Aujourd’hui, nous allons nous concentrer sur Tableau Desktop et le nouveau modèle de données de la version 2020.2.
Découvrez dans cet article cette nouveauté qui permet de lier les données de manière simple et rapide sur la base de champs communs et non plus de fusionner les tables entre elles.
I – Nouveau modèle de données
1) Version pre-2020.2
a. La couche physique
Dans les anciennes versions pre-2020.2, il suffit de spécifier les tables physiques à utiliser et les jointures qui les relient pour les fusionner ensemble. Il s’agit d’un travail sur une couche physique.
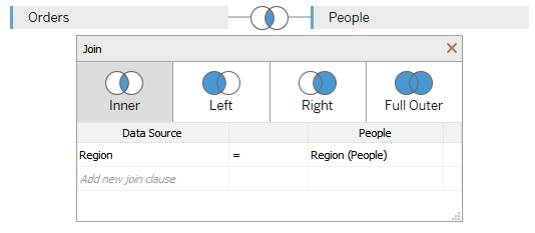
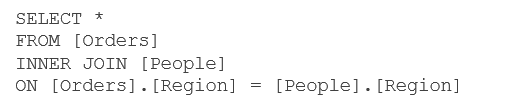
Quelque soit le graphe créé, Tableau utilisera toujours cette requête SQL comme base de requêtage, même si aucun des champs de la table physique People n’est utilisé dans la vue.
Par exemple, un diagramme en barre montrant les ventes par client génèrera la requête suivante.

b. Les inconvénients
- Requête complexe par des jointures non-nécessaires impactant les performances au lieu de sélectionner les données dans la table véritablement utilisée. (cas de modélisation à 5 tables et plus)
- Volumétrie conséquente par une potentielle démultiplication des lignes dans une relation 1 à N entre les tables physiques.
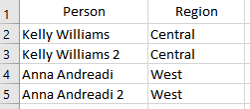
Supposons une nouvelle table physique People_M où pour chaque région deux personnes y sont rattachées. En utilisant le modèle précédent, chaque ligne de la table physique Order est dupliquée et le résultat des ventes est donc doublé.
Dans le cas d’une source avec des millions de lignes, l’impact peut être conséquent en termes de volumétrie et de performances.
- Impact sur les agrégations utilisées par la démultiplication des lignes
Dans le cas du graphe créé précédemment avec la table physique People_M, la valeur de l’agrégation des ventes par client est également doublée.
Une solution est d’utiliser un LOD. Mais les LODs sont des calculs un peu complexes générant des sous-requêtes et peu accessibles aux nouveaux utilisateurs Tableau quand bien même l’utilisateur détecte la démultiplication des lignes.
2) Version 2020.2
a. La couche logique
Ce nouveau modèle de données est différent et travaille sur les relations entre des tables logiques. Désormais, Tableau génèrera une requête SQL unique pour chaque vue prenant en compte les champs utilisés et non plus la totalité du modèle. Il s’agit d’un travail sur une couche logique.
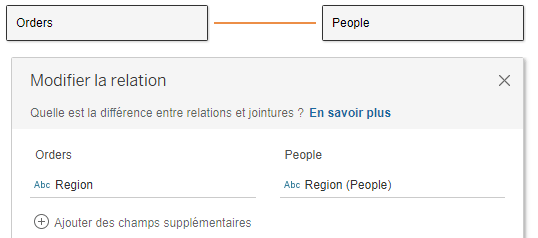
Il n’y a pas de diagramme de Venn entre les deux tables logiques ; il n’y a pas de jointure entre elles. Seule la relation entre les deux tables logiques est maintenue, ici, sur le champ [Region].
Les deux tables logiques sont indépendantes, il n’existe plus de requête SQL de base utilisée dans le classeur. Seule une notion de lien est renseignée et sera utilisée par Tableau pour construire les requêtes nécessaires pour chacune des vues.
b. Les adaptations
Par exemple, un diagramme en barre montrant les ventes par client génèrera la requête suivante :

- Adaptation de la requête à la vue et amélioration des performances.
Ici, les jointures inutiles se sont pas présentes et seule la table logique Orders est utilisée. La table logique People est donc exclue de la requête.
Dans le cas où, un filtre sur le champ [Person] de la table logique People est rajouté dans la vue où [Person] = « Kelly Williams », Tableau génère une requête avec une jointure entre les tables logiques Orders et People :

- Dans le cas d’une relation 1 à N:
La volumétrie n’est plus un problème, puisque chaque table logique est adressée indépendamment des autres ; il n’y a plus de démultiplication des données.
Concernant les agrégations, en reprenant l’exemple avec la table logique People_M, la requête reste inchangée puisque la vue n’utilise pas cette table. Plus besoin de LOD !
Supposons qu’un filtre de la table logique People_M est utilisé où [Person] = « Kelly Williams 2 », Tableau génère la requête suivante :
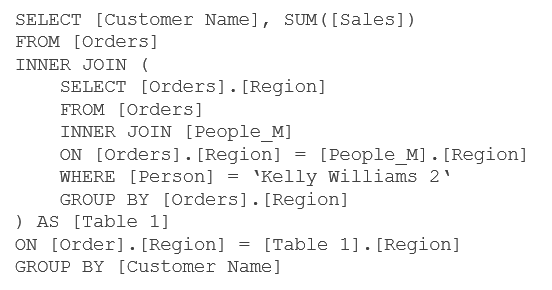
Tableau détecte une relation 1 à N et décide d’éviter une jointure entre les tables logiques Order et People_M en créant une sous-requête :

Cette sous-requête retourne simplement le champ [Region], qui est utilisé pour la jointure.
Le résultat est une table logique, ici Table 1, contenant 1 ligne et 1 colonne. Il n’y a plus de démultiplication de lignes et donc plus de démultiplication de la valeur des agrégations.
- Possibilité d’utiliser l’ancien modèle. S’il est nécessaire dans la modélisation d’utiliser une jointure, il est toujours possible d’ajouter en amont de la couche logique une couche physique en cliquant sur l’une des tables logiques et d’ajouter des tables sur la couche physique.
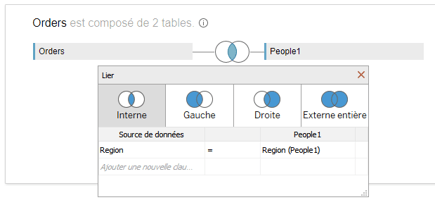
- Les options de performances sont des paramètres optionnels qui aident Tableau à optimiser les requêtes lors de l’analyse.
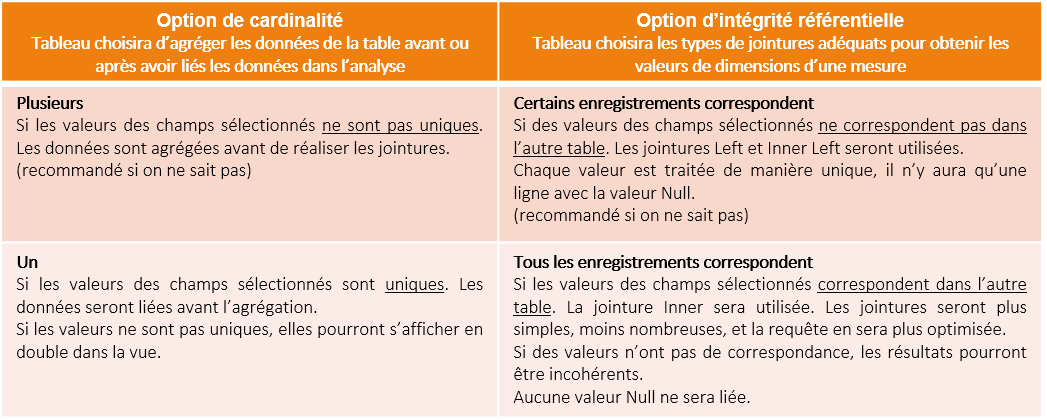
3) Contreparties du nouveau modèle
- /!\ ATTENTION /!\ Dans le cas où Tableau détecte une relation 1 à N et décide d’éviter une jointure entre les tables logiques Order et People_M, il créé une sous-requête. Cette sous-requête complexifie la requête finale. Il est parfois nécessaire de prendre le temps et de trouver un équilibre entre les différentes couches.
Il est parfois plus intéressant de passer par la couche physique que par la couche logique.
- Chaque table logique étant indépendante des autres, en sélectionnant une table dans l’onglet source de données, seuls les champs de cette table seront affichés.
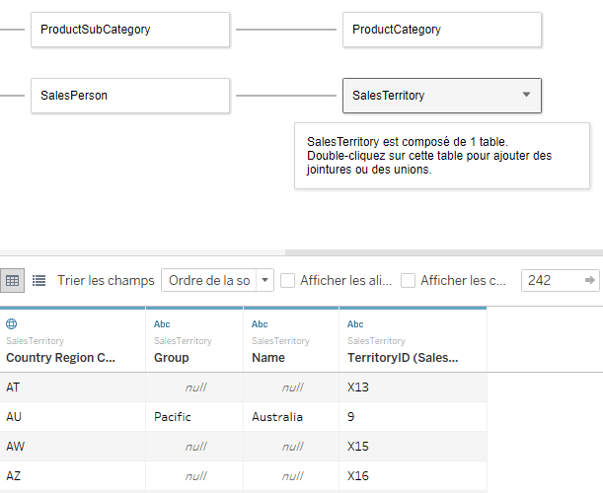
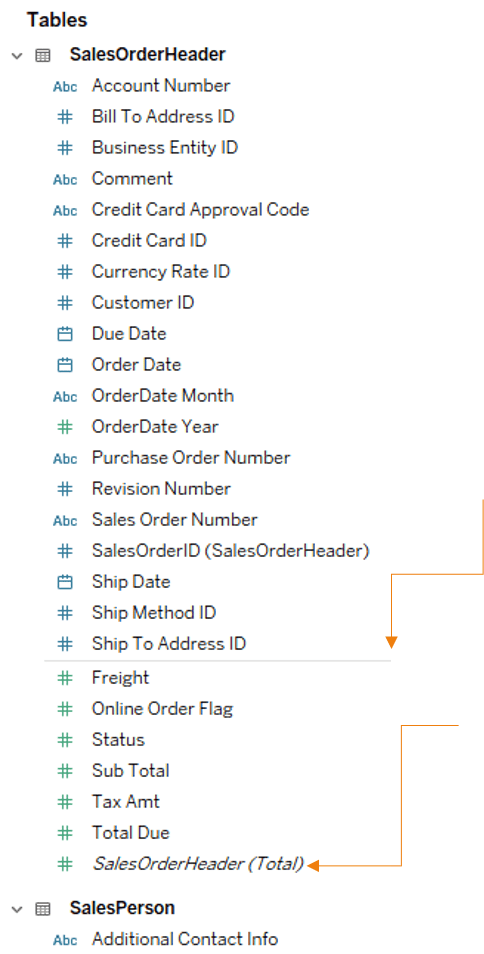
Dans une feuille, il n’y a plus de distinction entre les dimensions et les mesures, seulement une petite barre dans chaque table permet de les séparer.
Le champ généré Nombre de lignes, n’existe plus, mais il est remplacé par un champ généré automatiquement par Tableau pour chaque table logique portant le nom de la table (Total).
Il s’agit du nombre de lignes de la table.
II – Les différences par l’exemple
1) Commerciaux et Quota Mensuel
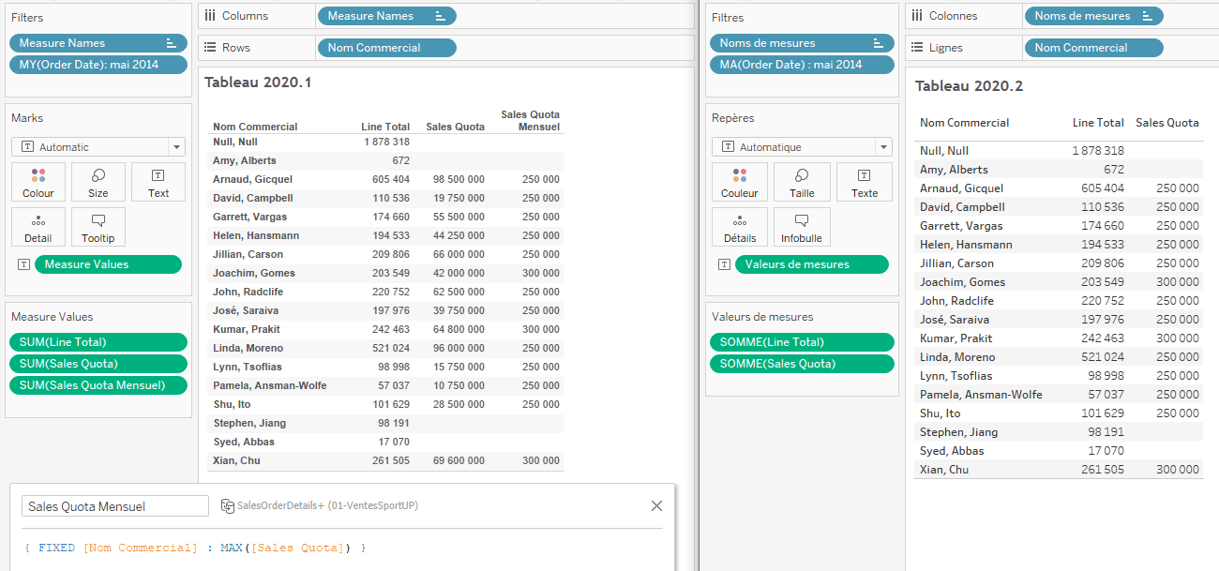
a. Version pre-2020.2
- On remarque que le résultat du quota mensuel est une somme de [Sales Quota].
- Comme la valeur est la même pour chaque ligne de commande, il est nécessaire de créer un LOD FIXED sur [Nom Commercial] et de récupérer le MAX de [Sales Quota] afin d’avoir le véritable quota mensuel de chaque commercial. Ce champ s’appelle [Sale Quota Mensuel].
b. Version 2020.2
- Dans la version Tableau 2020.2, les tables logiques sont indépendantes.
- La valeur de [Sales Quota] n’a pas besoin d’être fixée par un LOD.
2) Commerciaux et Ratio Ventes/Quota Mensuel
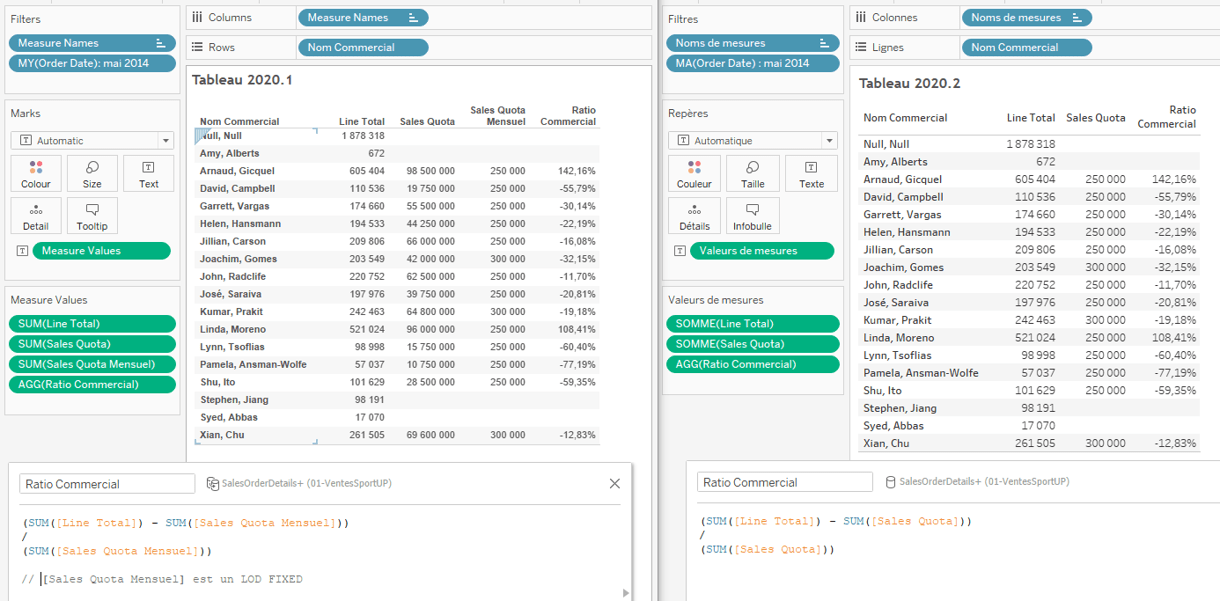
a. Version pre-2020.2
- Pour créer le champ [Ratio Commercial], il est nécessaire de faire appel au champ [Sales Quota Mensuel], calculé avec un LOD FIXED.
- Cela signifie que pour créer le champ [Ratio Commercial], Tableau fait appel au calcul du FIXED à quatre reprises pour pouvoir créer le champ [Sales Quota Mensuel].
- Les performances de Tableau en sont impactées.
b. Version 2020.2
- Pour le calcul de [Ratio Commercial], le champ [Sales Quota] suffit. La valeur de [Sales Quota] n’a pas besoin d’être fixée par un LOD.
- Cela signifie que pour créer le champ [Ratio Commercial], Tableau fait appel au champ [Sales Quota] de la source de données.
- Les performances de Tableau ne seront pas impactées par des calculs supplémentaires.
III – Conclusion
- Le nouveau modèle de données de Tableau est un modèle logique, mais il est toujours possible d’utiliser dans chaque table logique un modèle physique.
- Le modèle logique permet d’adresser des tables de granularités différentes sans avoir recourt au LOD.
- La migration d’une version antérieure à 2020.2, n’impactera pas le modèle que vous avez créé. L’ancienne modélisation physique sera encapsulée dans le modèle logique.
- Dans une feuille, les données sont réparties par table logique et non plus en dimensions et mesures. La séparation entre les dimensions et mesures est représentée dans chaque table par une barre grise.
- Le champ Number of Reccords n’existe plus. Chaque table logique dispose désormais d’un champ généré automatiquement qui retourne le nombre de lignes de la table logique.
Author Profile





